Automate Your Splunk Queries with splunk_query_runner
Are you tired of running repetitive queries in Splunk manually? Do you need a way to schedule and automate the export of your results? Introducing splunk_query_runner, a lightweight command-line utility designed to simplify Splunk querying and output management.
With this tool, you can use a CSV input file along with your authentication token for seamless operation. It’s perfect for automation pipelines, scheduled reporting, or simply reducing the effort involved in repetitive query tasks. You can download the app and find more information in the GitHub repository.
What is splunk_query_runner?
The splunk_query_runner is a command-line tool designed to simplify and automate the execution of Splunk searches via the REST API. Instead of logging into the Splunk Web UI, copying queries, setting time ranges, and exporting results manually, this tool allows you to define everything once in a CSV file and run it with a single command.
At its core, it functions as a lightweight scheduler and execution engine for Splunk searches. You prepare a list of searches (SPL), time ranges, and output preferences in a structured CSV file. The tool then parses this file, authenticates to Splunk using your token or credentials, executes each query, and saves the results to local files in your chosen format (CSV or JSON).
Whether you’re querying index searches (index=xxx), saved searches (| savedsearch), data model queries (| tstats), or database queries (| dbxquery), the splunk_query_runner can handle them all. It is particularly useful for automating reports, scheduling routine data pulls, or integrating Splunk data into external systems without the need to set up complex workflows.
Additionally, the project includes helpful scripts to:
- Generate authentication tokens (
create_splunk_tokens) - Dynamically update time ranges if you are trying to schedule reports (
update_dates_for_input_files) - Clean up old outputs and orchestrate the entire process (
all_runner_script)
Whether you are a developer automating security reports, a data engineer scheduling exports, or a Splunk administrator running batch jobs, the splunk_query_runner can streamline your workflow with minimal setup and maximum flexibility.
Key Features
- Run Splunk queries using the REST API
- Supports token-based authentication and username/password authentication
- Handles rising-column dbxquery scenarios
- Compatible with tstats, indexed searches, and saved searches
- Outputs in CSV or JSON formats
- Offers CLI support with configurable input and output paths
- Enables time-based automation with dynamic date updates
How it works
The process begins by executing the all_runner_script. This script prepares the necessary environment, updates the dates in the input CSV file, and deletes any old output files. Once the environment is ready, it runs the Python script splunk_query_runner.py (So don’t forget to install python 😊 and change the mode of all files to be executed).
The Python script reads queries from the input_list.csv file, establishes a connection to the Splunk instance using either an authentication token or user credentials from the user.conf file, and then executes the queries. The results are saved in the specified output format, either CSV or JSON.
That’s enough seriousness. Now let’s examine the app with a use-case. 😊
1. Step: What we want?
At this stage, let’s set up a scenario where we want four queries to run every day, as detailed below. Note that I’ve already defined a mysql-local connection and created a database table named internal_mysql_tests, along with a saved search called Endpoint - oyku-xxx - Rule. If you don’t have similar examples, I recommend creating them first.
╔═══════════════════════════╦═════════════════════════════════════════════════════════════════════════╦════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ Search/File Name ║ Description ║ SPL ║
╠═══════════════════════════╬═════════════════════════════════════════════════════════════════════════╬════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║ my_internal_search_result ║ index search usage example ║ index=_internal earliest=-15m | table host, log_level, sourcetype, _time| head 15 ║
║ my_tstats_result ║ tstats command usage example ║ |tstats count where index=_internal by sourcetype| head 5 ║
║ my_savedsearch_result ║ savedsearch (e.g., correlation search / detection, ...) command example ║ | savedsearch "Endpoint - oyku-xxx - Rule" ║
║ my_dbxquery_result ║ dbxquery command usage example ║ | dbxquery connection=mysql-local query="SELECT * FROM `internal_tests`.`internal_mysql_tests` WHERE timestamp > ? ORDER BY timestamp ASC ║
║ there_is_no_such_an_index ║ Example that will not return data ║ index=no_such_an_index ║
╚═══════════════════════════╩═════════════════════════════════════════════════════════════════════════╩════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝
To run multiple searches efficiently, you’ll need to define them in a structured input CSV file. Let’s assume our file is named input_list.csv. Each row in the file represents a separate search job with its time range, query, and output preferences.
Here’s an example:
title;earliest_date;earliest_time;latest_date;latest_time;spl;output_format;param
my_internal_search_result;01/09/2025;00:00:00;02/09/2025;00:00:00;index=_internal earliest=-15m | table host, log_level, sourcetype, _time | head 15;csv;false
my_tstats_result;01/09/2025;00:00:00;02/09/2025;00:00:00;|tstats count where index=_internal by sourcetype | head 5;csv;false
my_savedsearch_result;01/09/2025;00:00:00;02/09/2025;00:00:00;| savedsearch "Endpoint - oyku-xxx - Rule";csv;false
my_dbxquery_result;01/09/2025;00:00:00;02/09/2025;00:00:00;| dbxquery connection=mysql-local query="SELECT * FROM `internal_tests`.`internal_mysql_tests` WHERE timestamp > ? ORDER BY timestamp ASC" params="2025-09-02 17:05:39";csv;true
there_is_no_such_an_index;01/09/2025;00:00:00;02/09/2025;00:00:00;index=no_such_an_index;csv;false
Column Descriptions
- title: Static prefix used in naming the output file. The full filename includes a timestamp range (e.g., my_internal_search_result-01092025T000000_03092025T000000.csv).
- earliest_date / earliest_time: Define the starting point of the search window (%d/%m/%Y, %H:%M:%S).
- latest_date / latest_time: Define the end point of the search window.
- spl: The actual Splunk query (SPL) to be executed. Must be valid and runnable in the Splunk UI.
- output_format: Desired output format – either csv or json.
- param: Set to true if the query contains parameterized timestamps (e.g., in dbxquery); otherwise, set to false.
In this step, we don’t need to worry about our earliest_date, earliest_time, latest_date, latest_time values. We will update them in the next step.
2. Step: Configure authentication
By default, splunk_query_runner uses a Splunk authentication token stored in the user.conf file. This is the recommended and most secure method, especially for automated environments where you want to avoid exposing passwords or entering credentials manually each time.
The user.conf file should include a single line like:
eyJraWQiOiJzcGx1bmsuc2VjcmV0IiwiYWxnIjoiSFM1MTIiLCJ2ZXIiOiJ2MiIsInR0eXAiOiJzdGF0aWMifQ.eyJpc3MiOiJhZG1pbiBmcm9tIE95a3UuaG9tZSIsInN1YiI6InNwbHVua19xdWVyeV91c2VyIiwiYXVkIjoic3BsdW5rLXF1ZXJ5LXJ1bm5lciIsImlkcCI6IlNwbHVuayIsImp0aSI6IjgwMmMwZTFiYTViOThasdE1ZDZkYTA4ZGIzZGYxNGIxYmYyY2I3ZTc5YWRiZjhmNjRkMjQ1ZThmN2MxMzkzYWEiLCJpYXQiOjE3NTc2ODA2MTIsImV4cCI6MTc1NzY4MTIxMiwibmJyIjoxNzU3NjgwNjEyfQ.bdzfbzkGCIpu7uHmYkVaPVeMTatIQ9NhmleReEnCGMFdqKgEDu1_BdiCJgHcdB68P7TAnzXCtcL996ab1J-2kQ
If you don’t know how to create an authentication token, you can use the create_splunk_tokens script, and you should probably check the Splunk official documentation about it. You can choose to use a different user account specifically for this job with the user role. Alternatively, you should add specific roles appropriate for your situation. Additionally, since roles may vary across different versions of Splunk, I recommend checking the Splunk documentation for more information.
If you prefer or are required to use basic authentication with a Splunk username and password, the script can accommodate that as well. To enable this feature, open the splunk_query_runner.py file and uncomment the relevant lines (typically around lines 12 and 23–37). Once activated, the script will prompt you to securely enter your username and password at runtime instead of pulling a token from a file.
⚠️ Important: I chose not to include user and password information in a file for security reasons. However, if you want to use this automated script with a username and password configuration method on a daily basis, you can add some lines to the splunk_query_runner.py script, although I do not recommend doing this.
3. Step: Run Everything with One Command
After your input file is prepared and authentication is set up, you can run the entire process with just one command. The included bash script, named all_runner_script, automates everything for you—there’s no need to manually update dates, clean folders, or enter lengthy commands.
./all_runner_script
The script carries out the following steps automatically, in order:
1. Creates the Output Directory (if necessary)
The script checks whether the outputs/ directory exists and creates it if it doesn’t. This folder is where all your result files will be saved, either in CSV or JSON format.
2. Updates Time Ranges in the Input File
If you’re using dynamic time windows (default: from “yesterday 00:00” to “today 00:00”), the script can automatically update the earliest_date and latest_date fields (params timestamp for the dbxquery function if you select true for the param value) in your input CSV file using the helper script update_dates_for_input_files. This feature ensures that your searches are always scheduled to run against the most recent data—ideal for daily or hourly jobs.
If you are using dynamic time windows, such as “yesterday to today,” the script can automatically update the earliest_date and latest_date fields in your input CSV file by using the helper script update_dates_for_input_files. Additionally, it modifies the parameter used in the dbxquery function if you select true for the param value. Please note that the parameters are only valid for the “%Y-%m-%d %H:%M:%S” timestamp format. If you want to change this format or other details, you will need to modify some code in the update_dates_for_input_files script. This feature ensures that your searches are always scheduled to run against the most recent data, making it ideal for daily or hourly jobs.
before running the script:
title;earliest_date;earliest_time;latest_date;latest_time;spl;output_format;param
my_internal_search_result;01/09/2025;00:00:00;02/09/2025;00:00:00;index=_internal earliest=-15m | table host, log_level, sourcetype, _time | head 15;csv;false
my_tstats_result;01/09/2025;00:00:00;02/09/2025;00:00:00;|tstats count where index=_internal by sourcetype | head 5;csv;false
my_savedsearch_result;01/09/2025;00:00:00;02/09/2025;00:00:00;| savedsearch "Endpoint - oyku-xxx - Rule";csv;false
my_dbxquery_result;01/09/2025;00:00:00;02/09/2025;00:00:00;| dbxquery connection=mysql-local query="SELECT * FROM `internal_tests`.`internal_mysql_tests` WHERE timestamp > ? ORDER BY timestamp ASC" params="2025-09-02 17:05:39";csv;true
there_is_no_such_an_index;01/09/2025;00:00:00;02/09/2025;00:00:00;index=no_such_an_index;csv;false
after running the script:
title;earliest_date;earliest_time;latest_date;latest_time;spl;output_format;param
my_internal_search_result;11/09/2025;00:00:00;12/09/2025;00:00:00;index=_internal earliest=-15m | table host, log_level, sourcetype, _time | head 15;csv;false
my_tstats_result;11/09/2025;00:00:00;12/09/2025;00:00:00;|tstats count where index=_internal by sourcetype | head 5;csv;false
my_savedsearch_result;11/09/2025;00:00:00;12/09/2025;00:00:00;| savedsearch "Endpoint - oyku-xxx - Rule";csv;false
my_dbxquery_result;11/09/2025;00:00:00;12/09/2025;00:00:00;| dbxquery connection=mysql-local query="SELECT * FROM `internal_tests`.`internal_mysql_tests` WHERE timestamp > ? ORDER BY timestamp ASC" params="2025-09-11 13:04:35";csv;true
there_is_no_such_an_index;11/09/2025;00:00:00;12/09/2025;00:00:00;index=no_such_an_index;csv;false
3. Deletes Old Output Files
To maintain organization and avoid confusion, the script removes old result files in the outputs/ folder before generating new ones. This way, you are always working with fresh data.
4. Runs the Python Script with All Parameters
Finally, the script calls the main Python script (splunk_query_runner.py) with all necessary arguments, including the input file, time format, host, and token file. The Python script then:
- Reads each row in your input CSV
- Converts date and time into UNIX timestamps
- Connects to Splunk using the provided credentials/token
- Executes the SPL query
- Saves the results in the specified format with a timestamped filename
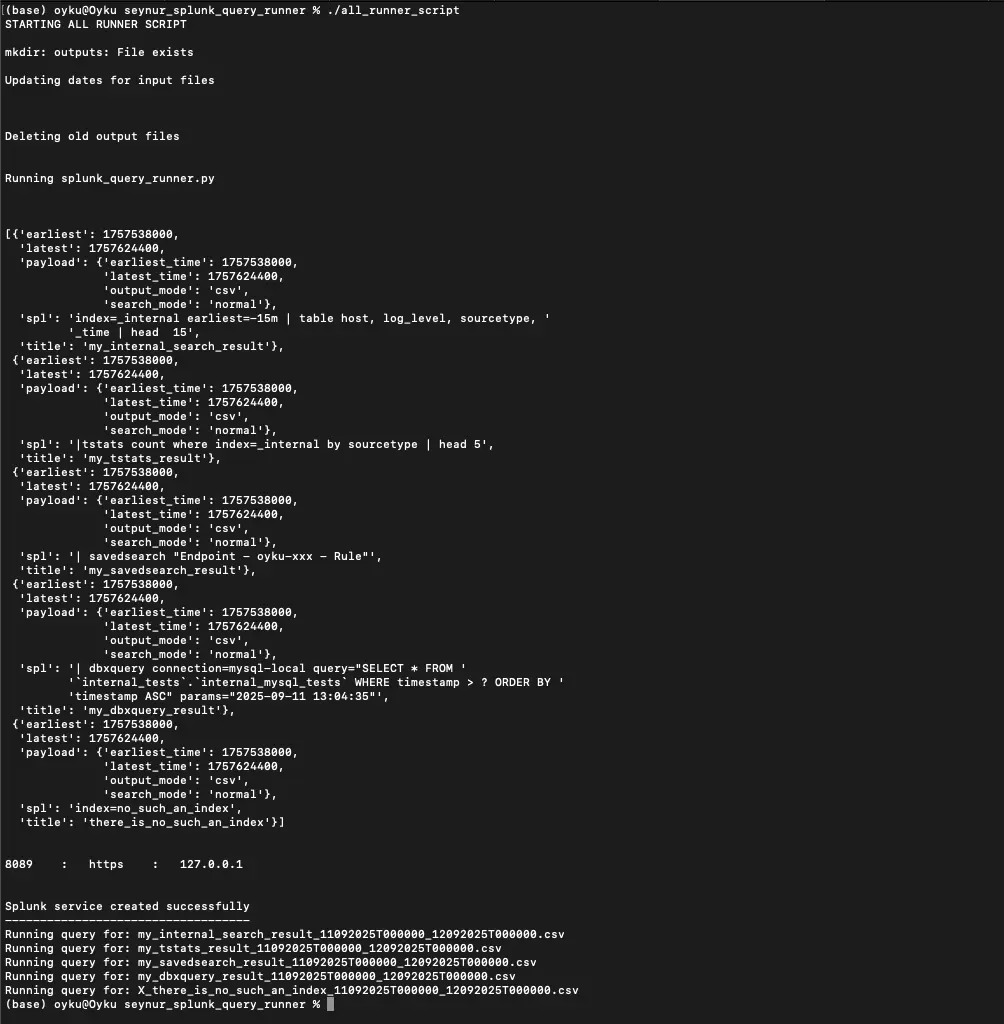 |
|---|
| Figure 1 Terminal output showing multiple searches running and file names being generated. |
⚠️ Important: Be aware that if a file name starts with X_ as image below (X_there_is_no_such_an_index_11092025T000000_12092025T000000), it may be empty. Therefore, you should verify your query.
Sample Cli-Output:
Running query for: my_internal_search_result_11092025T000000_12092025T000000.csv
Running query for: my_tstats_result_11092025T000000_12092025T000000.csv
Running query for: my_savedsearch_result_11092025T000000_12092025T000000.csv
Running query for: my_dbxquery_result_11092025T000000_12092025T000000.csv
Running query for: X_there_is_no_such_an_index_11092025T000000_12092025T000000.csv
This all-in-one approach makes it easy to integrate Splunk query automation into your daily workflow, cron jobs, CI/CD pipelines, or external data processing chains—with minimal manual intervention.
🔁 Want to run it every day? Just schedule ./all_runner_script with cron, systemd, or any scheduler of your choice.
Final Thoughts
If you regularly work with Splunk and manage multiple queries across different time ranges, environments, or formats, then splunk_query_runner can be an essential tool in your toolkit.
Instead of manually logging into the Splunk Web UI, adjusting time pickers, re-running saved searches, or exporting results manually, this tool allows you to automate the entire process safely, reliably, and at scale.
Whether you are:
- 🛠 A developer building automated pipelines for data extraction
- 📊 A data analyst scheduling periodic reports from Splunk
- 🔒 A security engineer running saved correlation searches
- 🧪 A tester verifying search performance across environments
- 📤 Or just someone who wants clean and reliable query output every day
splunk_query_runner is designed to meet your needs.
It not only supports standard searches but also advanced use cases like:
- ✅ Running saved searches with dynamic parameters
- ✅ Executing dbxquery commands that require rising columns
- ✅ Handling large-scale tstats aggregations with minimal overhead
- ✅ Managing outputs cleanly and consistently using timestamped filenames
- ✅ Switching between token-based and credential-based authentication
It’s quick to set up, easy to extend, and flexible enough to integrate with scheduling tools like cron, Airflow, or even CI/CD systems.
If you believe in automation and reproducibility, this tool will quickly become your go-to solution for interacting with Splunk from the command line.
Ready to Get Started?
Head over to the repository, clone it, and try it out in your environment:
👉 Get Started with splunk_query_runner on GitHub
Contributions and feedback are welcome. Feel free to fork it, customize it, and share how you’ve used it in your own projects! Also, if you encounter any problems or have questions about the topics discussed in this blog, feel free to contact me via my LinkedIn account.
Now it’s your turn — spin it up, break it, recover it, and learn from it. 😊
Happy Splunking! 🚀
References:
- [1] Seynur. (2025). seynur-tools/splunk_query_runner. Github. https://github.com/seynur/seynur-tools/tree/main/splunk_query_runner
- [2] Splunk. (2025). Use authentication tokens https://help.splunk.com/en/splunk-enterprise/administer/manage-users-and-security/9.4/authenticate-into-the-splunk-platform-with-tokens/use-authentication-tokens
- [3] Splunk. (2025). About users and roles https://help.splunk.com/en/splunk-enterprise/administer/admin-manual/9.3/manage-users/about-users-and-roles