Kafka + S3: Long-term searchable/queryable data retention

The goal of this post is to provide an alternate solution for a question we have started to face with our clients. What is the best way to store event-data in a searchable/queryable way for long-term retention? Obviously “the best way” will depend on many factors and many vendors claim various solutions to be the optimum solution. I tried to focus on open-source projects that utilize S3 compatible object storage.
“To a man with a hammer, everything looks like a nail.” -Twain/Maslow/Kaplan/Baruch/Buddha/Unknown (The Law of the Instrument)
Here, I’d like to take a step back from details and provide an explanation for the “nail” we have at hand in the hopes of molding “a hammer”.
We provide data-driven cybersecurity and IT operations/observability solutions to our clients, meaning that we help them collect event data from various tools (e.g. proxy servers, firewalls, system logs, application logs, IDS/IPS, endpoint protection vendors, etc. ) to detect threats/issues, provide visibility, and take/automate actions.
The data type we deal with is mostly event-oriented and streaming data (application logs, system events, metrics, etc.) as mentioned above; event sizes usually range from a few hundred bytes to a few kilobytes, depending on the verbosity of the platforms. Also, most of our clients have on-premise deployments due to regulative requirements; hence, this post does not cover a solution specific to cloud vendors but should be applicable to any type of data for organizations utilizing on-prem as well as cloud deployments that require long-term retention.
The Nail at hand:
Due to regulations and legal requirements, some organizations need to keep this event data for up to 10 years and be able to query them when asked. With this in place, current organizations mainly face 2 problems: operational inefficiency and storage costs/feasibility.
Operational inefficiency: Most organizations keep this data in various archive storage options but retrieving this data from the archive appears to be a bigger challenge from time to time. Depending on what to fetch, it can even take days to get some data from the archive.
Storage costs/feasibility: If you have a 10GB/day data ingestion rate, then it is probably easier to simply purchase more disks to keep your data locally and it wouldn’t cost that much. On the other hand, if you have 5TB+/day data ingestion rate, then this becomes an issue.
Let’s assume that we want to retain 10 years’ worth of data on local storage using our analysis tool that simply keeps a 1:1 ratio on disk for storage* (i.e. 10GB/day requires 10GB HDD on local storage per day).
*Note: Different vendors provide different compression ratios and you can definitely calculate this based on what you currently have. Keeping the ratio as 1:1 is simple enough for providing an example.
10 GB/day for 10 years: 10 GB/day x 365 days/year x 10 years =~ 35 TB HDD
5 TB/day for 10 years: 5 TB/day x 365 days/year x 10 years = 18,250 TB HDD (~18 PB)
Obviously, storage costs associated with local disks will be considerably high in the second scenario. Even if an organization has enough budget to cover the costs, managing that much local disk on nodes becomes a feasibility issue. For example, let’s assume that we have 100 data nodes in a distributed system (e.g. databases, indexing technologies, etc.) to handle a 5 TB/day volume of data, in the second scenario we need about 182TB HDD per node to meet the long-term data retention requirement.
A Hammer:
Following a good design approach of low coupling and high cohesion, we can say that it would be best to separate compute and storage layers. This idea has been implemented successfully with many storage vendors as well as Hadoop distributions with HDFS. I chose S3 bucket storage for its simplicity and applicability to our use-case.
At a high level, our solution should be reliable (fault-tolerant for both hardware & software), scalable (ability to handle growing volume by horizontally scaling), and maintainable (simple and flexible) while addressing the issues mentioned above (operational inefficiency & storage costs/feasibility).
The proposed solution has Apache Kafka (I used Confluent distribution for testing) at the center since it has somewhat become the standard tool for distributed event streaming platform for our data pipeline. Then we have S3 compatible object storage for keeping our long-term data (I used AWS S3 for testing). I’d like to consider 2 options
Option 1: Confluent Kafka w/ Tiered Storage + ksqlDB Let’s consider what Confluent Platform 6.0 has to offer: Tiered Storage with S3. In this setup, you can utilize S3 buckets in addition to existing local storage options for long-term data retention. This is also searchable/queryable via ksqlDB.
Option 2: Kafka + S3 Sink Connector + Drill + Superset The other option is to use Kafka S3 Sink Connector and other (open-source) tools to query data. I used Apache Drill (schema-free SQL query engine) and Apache Superset (data exploration and visualization platform) for testing.
Both options are reliable and scalable solutions with distributed architectures and proven users. The maintainability aspect somewhat depends on how teams manage and administer the environments and can be subjective. In the end, I try to give some of my opinions on this point. As a proof of concept, since there are well-documented resources for Confluent tiered storage, my setup below focuses on the second option: Kafka + S3 + Drill
Setting up a test environment:
I used a single Linux (ubuntu 18.04) environment and AWS S3 account for test purposes. It is possible and probably preferable to utilize containers for deployment, but I chose to install them manually to have a better understanding of the tools’ directory structures and configuration files.
Confluent Kafka:
In my test environment, I used the Confluent Platform version; the setup is pretty straightforward, simply download the latest tar.gz file and follow the instructions here. I did the installation under my home directory (/home/selim/confluent/).
Once installed, I followed the instructions to generate data on pageviews and users topics, so that I can use them later for testing.
Apache Drill: You can download (https://drill.apache.org/download/) the latest version, I used 1.18 in this environment. Once extracted, you run the embedded version for testing.
tar xvzf apache-drill-1.18.0.tar.gz
bin/drill-embedded
Once started, you can run queries either from the command-line or from the web UI on port 8047 (default port for Drill). Apache Drill comes with a sample employee.json file for test purposes.
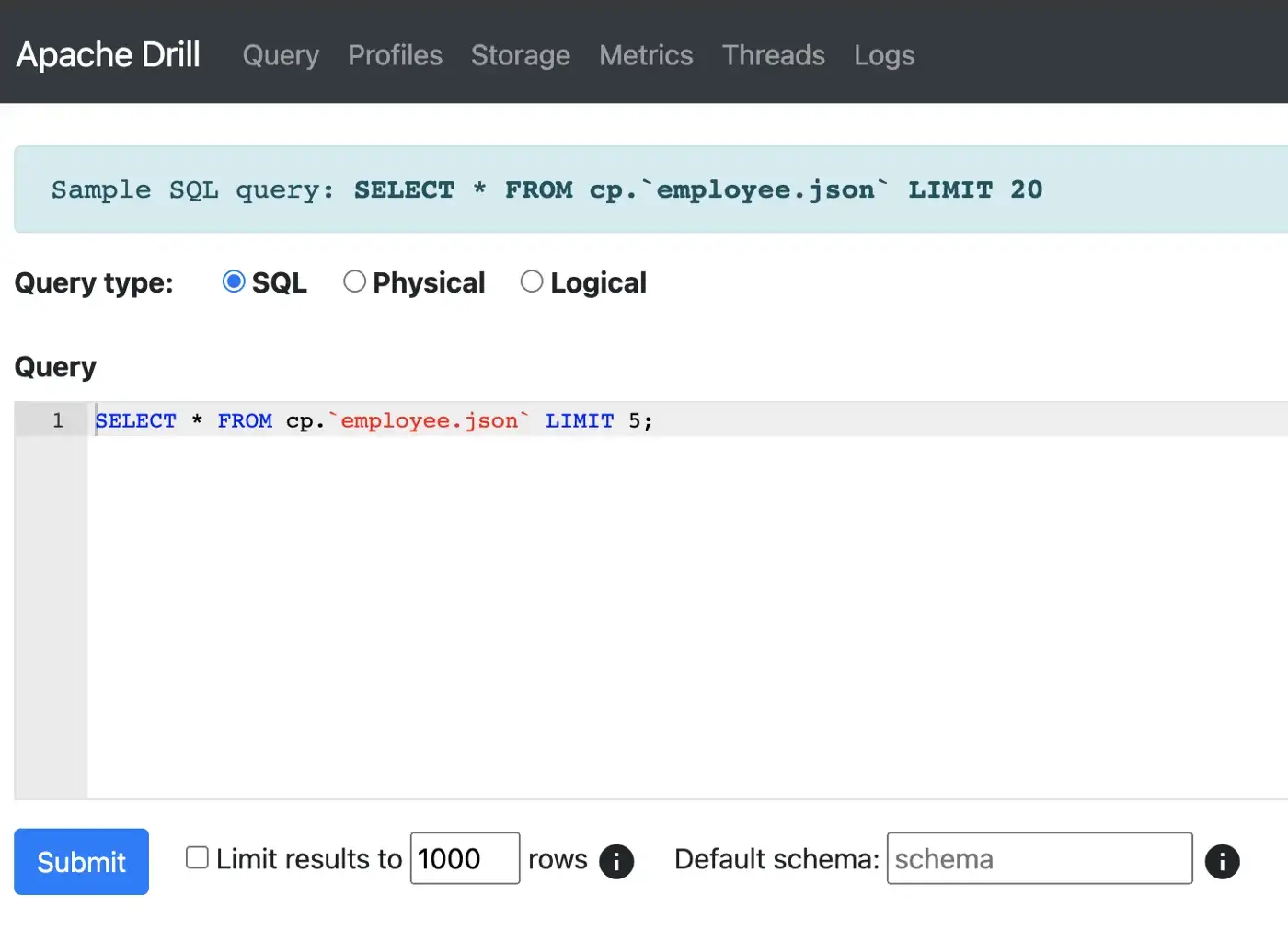
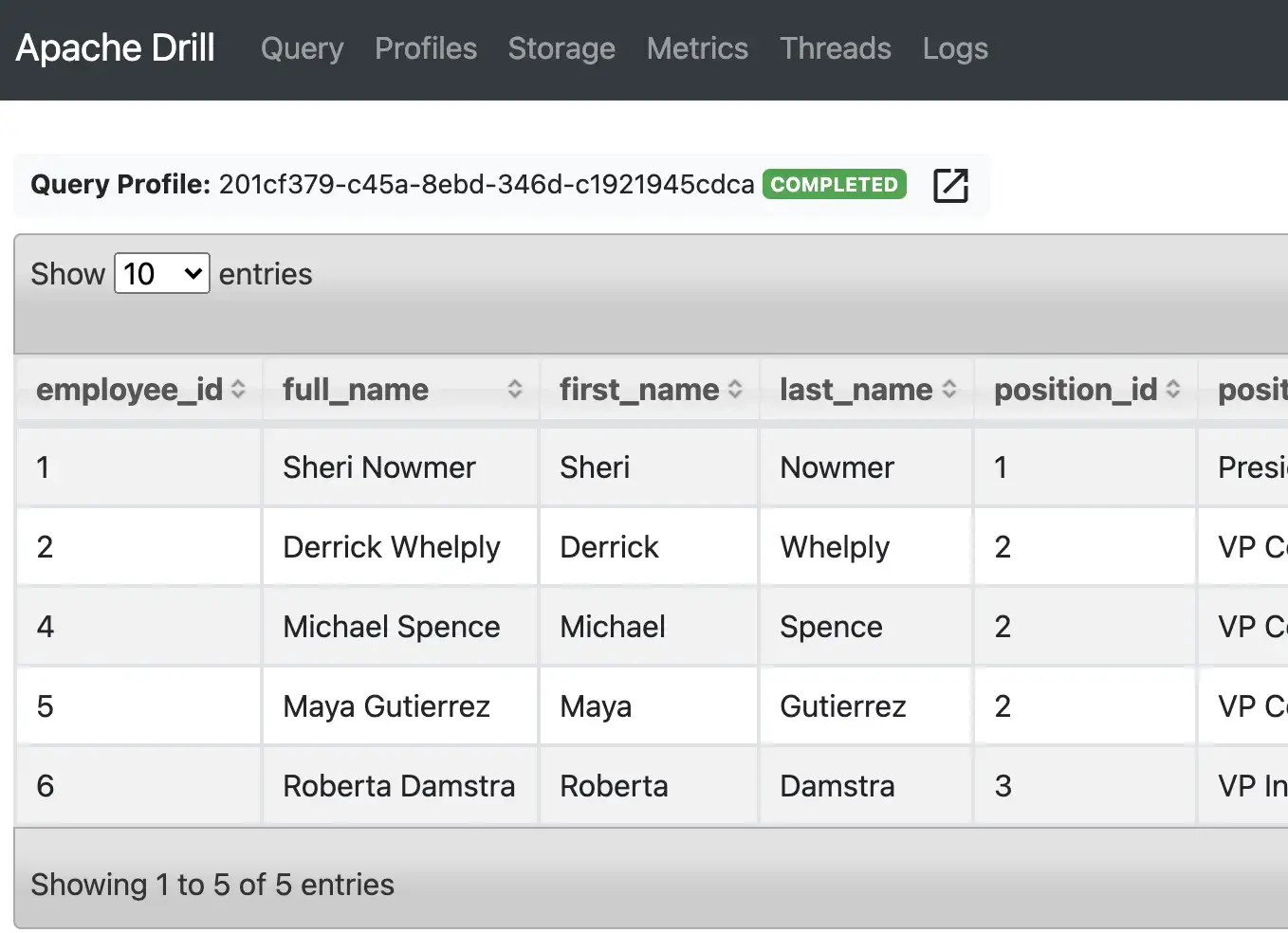
Apache Superset: You can follow the instructions to install this python application from scratch. The only difference is that I used virtualenvwrapper to create/manage the Python virtual environment and put the start command in a shell script.
# install dependencies
sudo apt-get install build-essential libssl-dev libffi-dev python-dev python-pip libsasl2-dev libldap2-dev
# create virtual environment
mkvirtualenv superset
# switch/activate the virtual environment
workon superset
# install superset
pip install apache-superset
superset db upgrade
#NOTE: If you see an error on the above command, please see below
# Create an admin user
export FLASK_APP=superset
superset fab create-admin
# init for defaults
superset init
Troubleshooting — error on “superset db ugprade” command: When I run the command, I figured that python was complaining about a specific import for “dataclasses”. Hence, I installed that as well :)
(superset) $> superset db upgrade
Traceback (most recent call last):
File "/home/selim/.virtualenvs/superset/bin/superset", line 5, in <module>
from superset.cli import superset
File "/home/selim/.virtualenvs/superset/lib/python3.6/site-packages/superset/__init__.py", line 21, in <module>
from superset.app import create_app
File "/home/selim/.virtualenvs/superset/lib/python3.6/site-packages/superset/app.py", line 45, in <module>
from superset.security import SupersetSecurityManager
File "/home/selim/.virtualenvs/superset/lib/python3.6/site-packages/superset/security/__init__.py", line 17, in <module>
from superset.security.manager import SupersetSecurityManager # noqa: F401
File "/home/selim/.virtualenvs/superset/lib/python3.6/site-packages/superset/security/manager.py", line 44, in <module>
from superset import sql_parse
File "/home/selim/.virtualenvs/superset/lib/python3.6/site-packages/superset/sql_parse.py", line 18, in <module>
from dataclasses import dataclass
ModuleNotFoundError: No module named 'dataclasses'
(superset) $> pip install dataclasses
Collecting dataclasses
Downloading dataclasses-0.8-py3-none-any.whl (19 kB)
Installing collected packages: dataclasses
Successfully installed dataclasses-0.8
(superset) $> superset db upgrade
Configuration & Running Superset:
You can set up your environment according to Superset documentation: Configuring Superset. In my environment, I created bin and etc directories with the following content.
(superset) $> ls -R
./bin:
run_superset_dev.sh
./etc:
superset_config.py
(superset) $> cat bin/run_superset_dev.sh
#!/bin/sh
export PYTHONPATH=$PYTHONPATH:/home/selim/apache/superset/etc
superset run -p 8088 -h 0.0.0.0
(superset) $> cat etc/superset_config.py
#---------------------------------------------------------
# Superset specific config
#---------------------------------------------------------
ROW_LIMIT = 5000
SUPERSET_WEBSERVER_PORT = 8088
FAB_UPDATE_PERMS = False
#---------------------------------------------------------
# Flask App Builder configuration
#---------------------------------------------------------
# Your App secret key
SECRET_KEY = '\2\1someappsecret\1\2\e\y\y\h'
# The SQLAlchemy connection string to your database backend
# This connection defines the path to the database that stores your
# superset metadata (slices, connections, tables, dashboards, ...).
# Note that the connection information to connect to the datasources
# you want to explore are managed directly in the web UI
# SQLALCHEMY_DATABASE_URI = 'sqlite:////path/to/superset.db'
SQLALCHEMY_DATABASE_URI = 'sqlite:////home/selim/.superset/superset.db'
# Flask-WTF flag for CSRF
WTF_CSRF_ENABLED = True
# Add endpoints that need to be exempt from CSRF protection
WTF_CSRF_EXEMPT_LIST = []
# A CSRF token that expires in 1 year
WTF_CSRF_TIME_LIMIT = 60 * 60 * 24 * 365
# Set this API key to enable Mapbox visualizations
MAPBOX_API_KEY = ''
(superset) $> bin/run_superset_dev.sh
AWS S3: We also need to create a test bucket on S3 so that we can send some data to it. You’ll need the credentials (access key and secret) from IAM Management Console as well.
Configuring components:
Now we have all the necessary components installed. Next, we need to ensure that they are all connected to each other. In this part, our goal is to make sure we send data from Kafka topics to S3 buckets and be able to query them as needed.
We have 2 options for this. Option 1 is to utilize Tiered Storage functionality that comes with Confluent Platform 6.0.0 (fully supported), which enables us to use ksqlDB to query data from S3. Option 2 is to use S3 Sink Connector with Apache Drill (and maybe Superset as well) to be able to query data from S3. As mentioned above, there are many well-written blogs about Tiered Storage functionality from Confluent; so, I’d like to skip the details and continue with option 2.
Option 1: Confluent Tiered Storage
Configure Kafka with Tiered Storage: Here’s the latest blog link for tiered storage functionality: Cloud-Like Flexibility and Infinite Storage with Confluent Tiered Storage and FlashBlade from Pure Storage
Configuring Confluent Kafka with Tiered Storage is well documented here, so I will not repeat it. However, here’s the server.properties configuration as an example.
$> tail -8 etc/kafka/server.properties
############ TIERED STORAGE - AWS S3 ################
confluent.tier.feature=true
confluent.tier.enable=true
confluent.tier.backend=S3
confluent.tier.s3.bucket=seynurtestbucket
confluent.tier.s3.region=eu-west-1
Once the configuration is in place, you can configure topics to use this option (e.g. ‘pageviews’ topic), then utilize ksqlDB to query your data.
Option 2: S3 Sink Connector + Apache Drill + Apache Superset
Configure Kafka with S3 Sink Connector: First, we need to install the connector as described here.
confluent-hub install confluentinc/kafka-connect-s3:latest
Do you want to install this into /home/selim/confluent/share/confluent-hub-components? (yN) y
Component's license:
Confluent Community License
http://www.confluent.io/confluent-community-license
I agree to the software license agreement (yN) y
Downloading component Kafka Connect S3 5.5.3, provided by Confluent, Inc. from Confluent Hub and installing into /home/selim/confluent/share/confluent-hub-components
Detected Worker's configs:
1. Standard: /home/selim/confluent/etc/kafka/connect-distributed.properties
2. Standard: /home/selim/confluent/etc/kafka/connect-standalone.properties
3. Standard: /home/selim/confluent/etc/schema-registry/connect-avro-distributed.properties
4. Standard: /home/selim/confluent/etc/schema-registry/connect-avro-standalone.properties
5. Based on CONFLUENT_CURRENT: /tmp/confluent.590273/connect/connect.properties
Do you want to update all detected configs? (yN) y
Adding installation directory to plugin path in the following files:
/home/selim/confluent/etc/kafka/connect-distributed.properties
/home/selim/confluent/etc/kafka/connect-standalone.properties
/home/selim/confluent/etc/schema-registry/connect-avro-distributed.properties
/home/selim/confluent/etc/schema-registry/connect-avro-standalone.properties
/tmp/confluent.590273/connect/connect.properties
Completed
After adding the S3 connector, I used the following settings for sending buckets to S3. Note that there are many configuration options for the S3 sink connector and it will definitely depend on your data, use-case, and requirements for the right setup.
{
"name": "s3sink-pageviews",
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"topics": [
"pageviews"
],
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"flush.size": "10",
"s3.bucket.name": "seynurtestbucket",
"s3.region": "eu-west-1",
"aws.access.key.id": "*************",
"aws.secret.access.key": "*************",
"storage.class": "io.confluent.connect.s3.storage.S3Storage"
}
The above example uses "flush.size" of 10 (invoke file commits every 10 records), which created many buckets with very small sizes on AWS; obviously, this needs to be tuned properly based on expected volume.
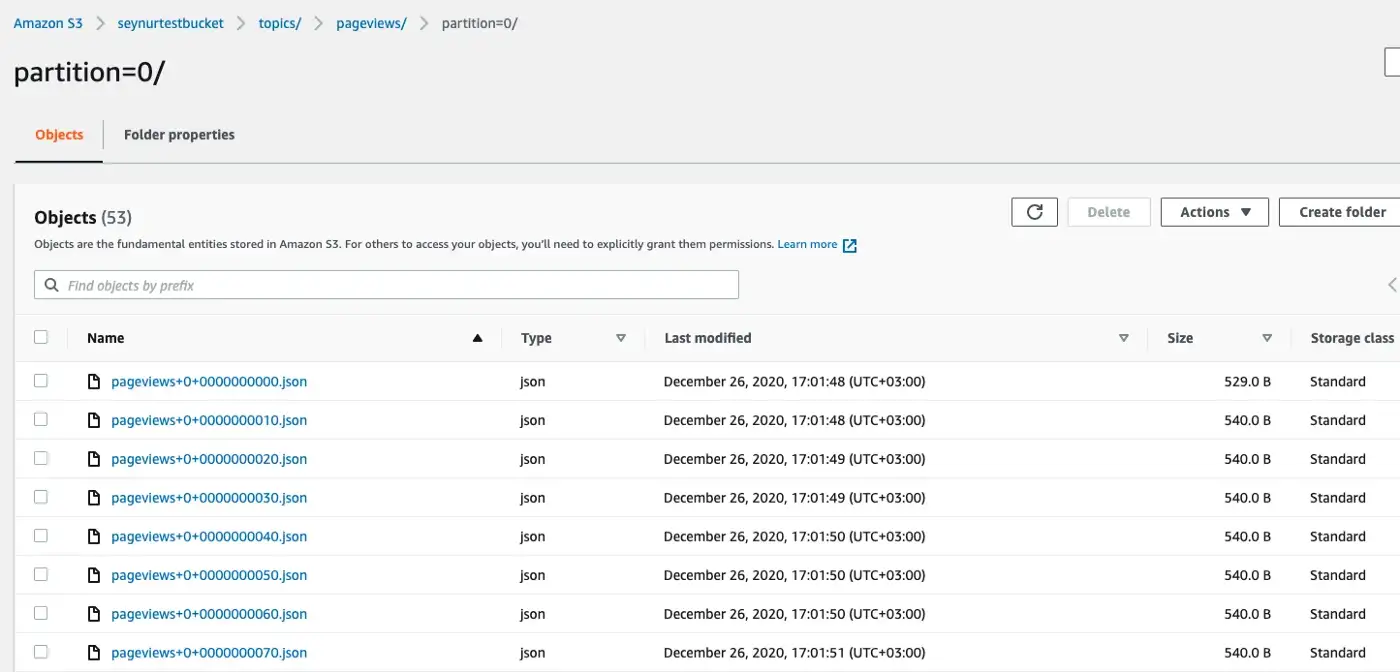
In this configuration example, I didn’t use any special property and by default, the files are created under topics/pageviews/partition=0/ directory structure. This can be dynamically updated according to your needs with TimeBasedPartitioner class. I used this one because it suits the use-case for long-term event data retention, grouped by dates.
{
"name": "s3sink-pageviews",
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"topics": [
"pageviews"
],
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"flush.size": "1000",
"s3.bucket.name": "seynurtestbucket",
"s3.region": "eu-west-1",
"aws.access.key.id": "***********",
"aws.secret.access.key": "***********",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"partition.duration.ms": "10000",
"path.format": "YYYY/MM/dd/HH",
"locale": "en-US",
"timezone": "+03:00",
"timestamp.field": "timestamp"
}
In the above example, path.format allowed us to set the directory structure so that we can now view the files within S3 as following, under proper year/month/date/hour folders.
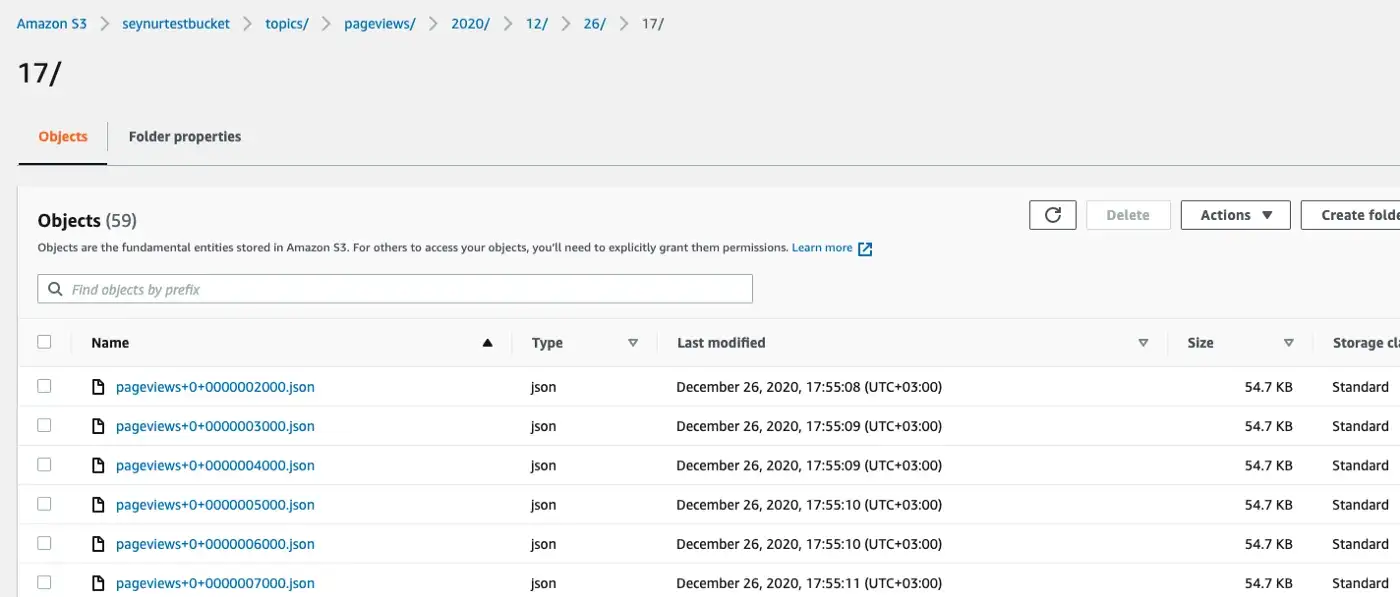
Configure Drill with S3: Apache Drill has many plugins to connect to various data sources and for connecting to S3 we will use S3 Storage Plugin. This is a simple configuration file where we provide the credentials and bucket information.
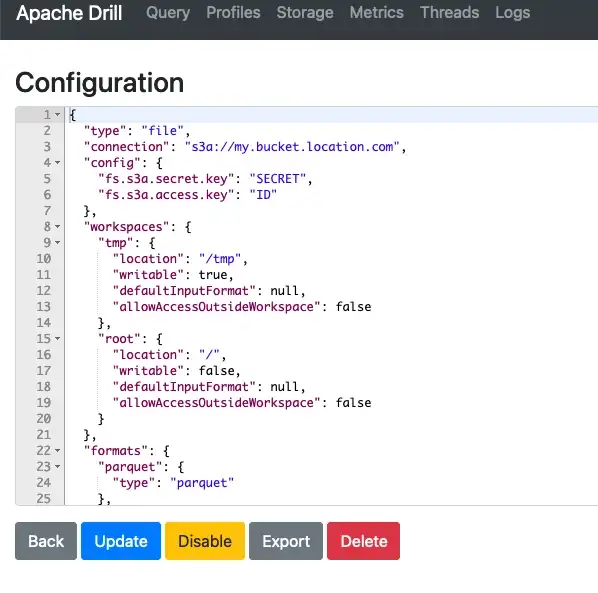
I used the following configuration for my environment.
{
"type": "file",
"connection": "s3a://seynurtestbucket/",
"config": {
"fs.s3a.secret.key": "********",
"fs.s3a.access.key": "********",
"fs.s3a.endpoint": "s3.eu-west-1.amazonaws.com"
},
...
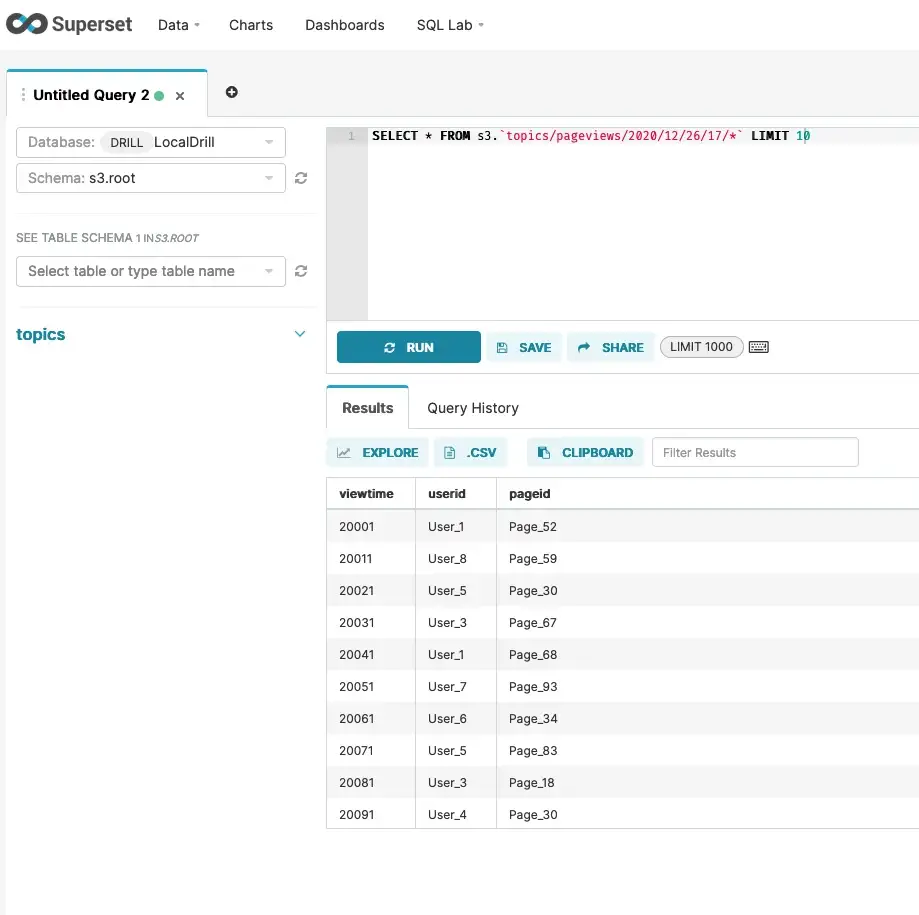
Running the following query would bring the results from a given date.
SELECT * FROM s3.`topics/pageviews/2020/12/26/17/*` LIMIT 10
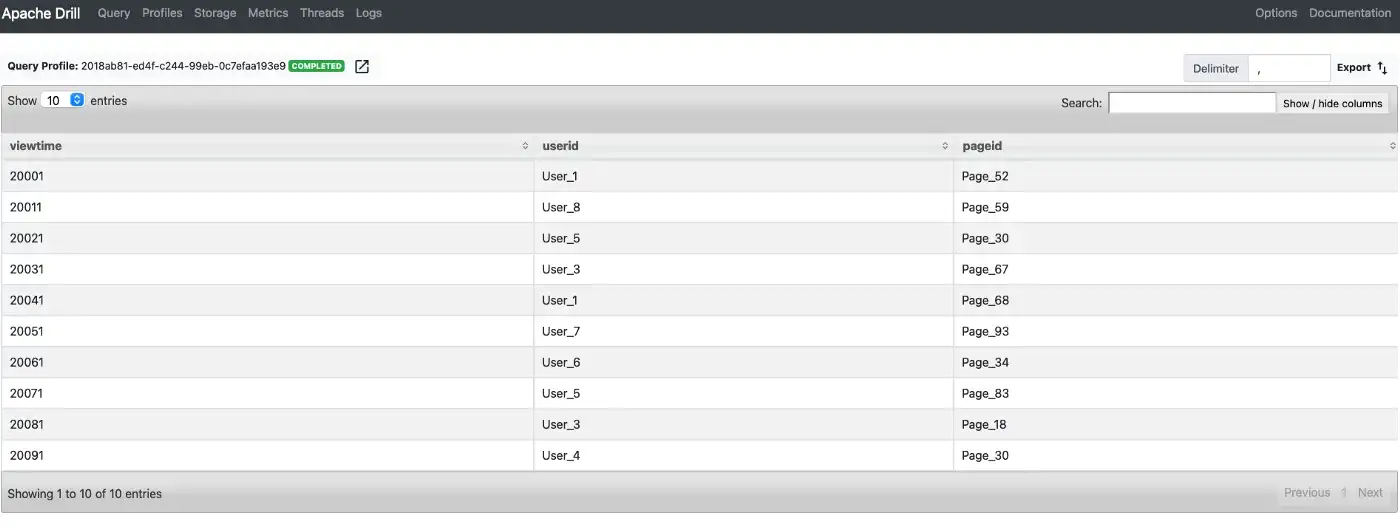
Configure Superset with Drill (optional): This is somewhat an optional step for running queries against our stored data in S3, but Superset allows us to utilize better visualizations with any aggregations we’d like to do. Custom applications or other tools can also be utilized to work with Apache Drill.
Configuring Superset to use Drill is pretty simple and documented here. From the Web UI, you’ll need to add a new Database. I used the following for my Apache Drill running in embedded mode.
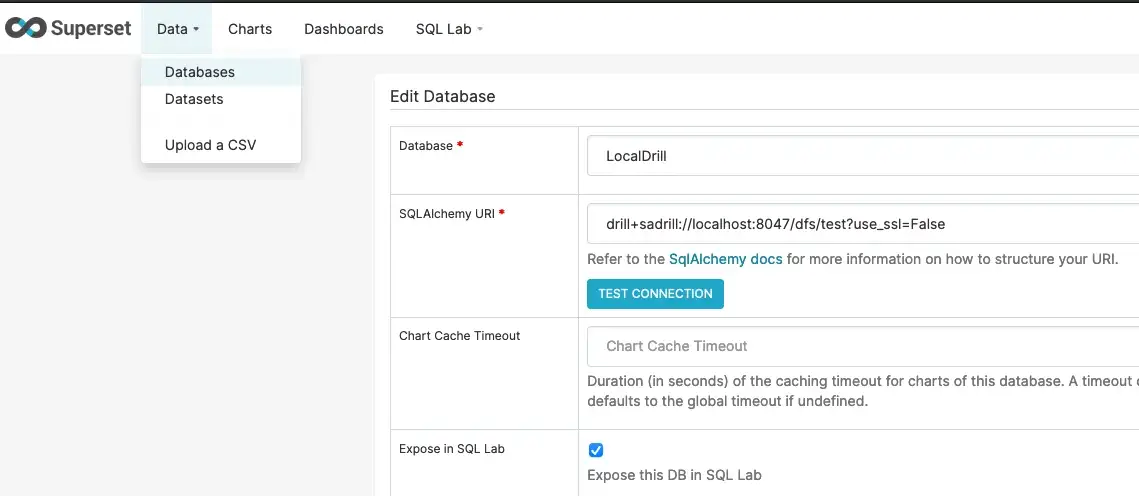
Now you can run the queries from Drill and build charts/dashboards if needed.
Conclusion and Other Considerations:
Our goal is to build a scalable, reliable, and maintainable data system while providing a solution to operational inefficiency and storage cost issues. Both mentioned options have data-driven architecture components that are proven to be scalable and reliable. Below, I tried to compare these alternatives based on our use-case.
Option 1: Confluent Kafka w/ Tiered Storage + ksqlDB
Advantages:
- Maintainability: Confluent Platform provides all needed components and makes it easier to maintain ongoing operations with fewer tools to manage
- Query: Once data is in Kafka, ksqlDB queries can be utilized for streaming data as well as historically stored data on S3 without needing to adjust to different data stores
Disadvantages:
- Tiered Storage functionality is available with Confluent Enterprise License/Subscription as a commercial feature. (this may also be considered as an advantage, depending on point of view)
- There are Known Limitations
- There aren’t any compression options available yet. Data is stored as the same size on S3 buckets as local disks.
Option 2: Kafka + S3 Sink Connector + Drill + Superset
Advantages:
- Other than S3 Sink Connector (Confluent Community License), all components can be run as 100% open-source with Apache License
- Minimizing storage space on S3 up to 8–15% (depending on data, codec, and compression). Various codec compression algorithms are supported:
- Avro (deflate, snappy, bzip2)
- parquet (gzip, snappy, lz4, brotli, zstd, lzo)
- JsonFormat or ByteArrayFormat (gzip)
Disadvantages:
- Maintainability: Open-source projects such as Drill and Superset will require additional resources for operations and well-defined conventions to make things work across multiple tools (e.g. defining archiving structures, security & RBAC, etc.).
Overall, the “perfect” solution will depend on the requirements and budget but I find option 2 more appealing for storing event data due to regulative requirements. Long-term data retention with the S3 sink connector is almost like a classical archive (in fact, with codec compressions it will take similar disk space as an archive that utilizes gzip), and being able to run and save queries with Superset will enable organizations to create self-serving platforms for their data. The response time will not be fast as searching on local data but we have Kafka and analytics platforms (Splunk, Elastic) for that purpose (ingest once, use many). It would definitely require some planning for teams to get ready for production in an enterprise and other tools such as Presto can be considered and compared as a part of the solution. Perhaps, I may try that in the near future.
This has been a rather long post and thanks for reading. Please feel free to comment or provide recommendations/corrections.