Restoring Archived Data with Splunk
Data retention policies help to manage organizations’ big data. Since the amount of data collected today is tremendous, establishing a retention policy is crucial as ingesting the correct data source. The retention policy is basically how long the organization wants to keep the data. When a retention policy is not developed for the ingested data, very rarely processed data takes up space in the system, which affects the performance and increases the cost of storage.
The retention policies for Splunk Enterprise indexes can be quickly arranged with sets of rules. Either delete the data, keep the data according to the storage amount, archive the data or keep the data as the regulations demand. What if you need to use the archived data?
Splunk Enterprise provides steps to restore archived data; however, this usually needs to be automated/scripted in practice, and with the number of buckets to restore the process can become a burden. In this post, you will find how to utilize https://github.com/seynur/restore-archive-for-splunk to make this process smoother.
How Splunk stores the indexes
Firstly, Splunk Enterprise stores indexed data in buckets, and an index typically consists of many buckets according to the age of the data. These index directories contain both the raw data and index files. Buckets move through stages as they age according to the retention policy. This policy can be either storage-based or time-based policy following the rules that are set.
As buckets age, they roll from hot bucket to thawed bucket;
- Hot
- Warm
- Cold
- Frozen
- Thawed
As a side note, buckets are automatically rolled from hot to frozen; however, thawed buckets indicate just that last stage a bucket can go through.
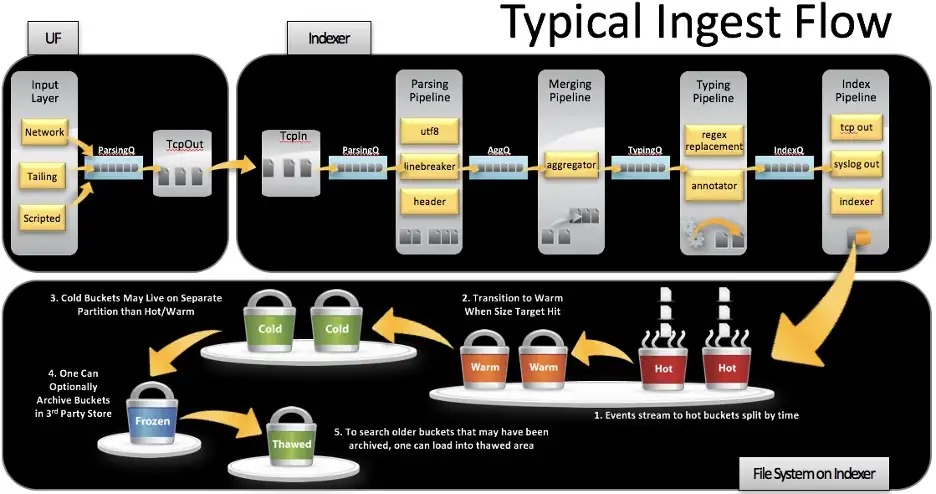
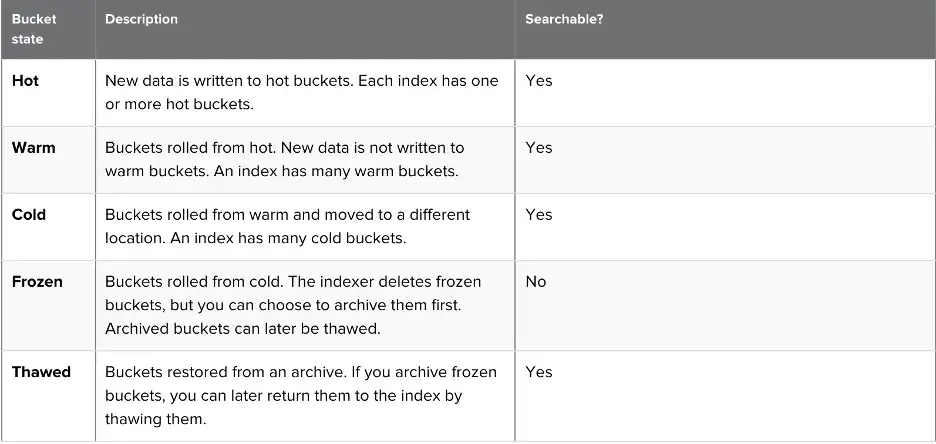
Bucket directories changes with aging. When cold buckets roll to frozen ones, they are either deleted or moved to the archive path. At this stage, the rebuilding process comes into the scene since the frozen buckets are not searchable.
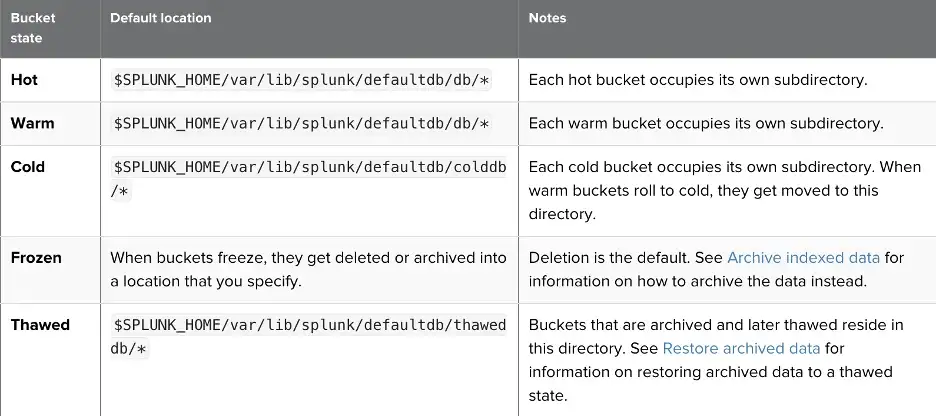
Also, bucket names are slightly different according to the non-clustered and clustered deployment.

While the newest time represents the latest event, the oldest time represents the first event time for that bucket in epoch time. Buckets starting with the “rb” are the replicated buckets for clustered buckets and “db” stands for the original buckets. Local id is the id of the buckets, and replicated buckets have the same id with the original one. Guid is used to distinguish which indexer has that bucket.
How Splunk restores the archived indexed data
The rebuilding process is simply to move the archived buckets in the frozen directory to the thawed directory. This process consists of three steps which are selecting the correct buckets according to time, copying them to the thawed path, and rebuilding them. For example, if you want to restore the Windows event logs, you can create the archived_windows index to avoid confusing the newest and archived events.
For *nix user;
- Copy the selected bucket into the thaweddb location of the index that you will be searching for archived events after rebuilding
cp -r db_1549226400_1549226400_7 /opt/splunk/var/lib/splunk/archived_windows/thaweddb
- Execute the “splunk rebuild” command
splunk rebuild /opt/splunk/var/lib/splunk/ archived_windows/thaweddb/db_1549226400_1549226400_7
- After rebuilding, restart Splunk Indexer
That being said, going through the epoch timestamps and selecting the correct time is not that easy if you think about the number of buckets that have been archived for an index.
There is an easier way: restore-archive-for-splunk
We’ve developed a script that can select the correct buckets according to the time range, copy them to the desired thaweddb directory and rebuild them. You can directly visit our GitHub page to view the “restore-archive-for-splunk” script.
Here are the required params for this script;
usage: restore-archive-for-splunk.py [-h] [-f FROZENDB] [-t THAWEDDB] [-i INDEX] [-o OLDEST_TIME] [-n NEWEST_TIME] [-s SPLUNK_HOME] [--restart_splunk] [--check_integrity] [--version]
Below is an example to restore a frozen index (regardless of the number of buckets involved):
python3 restore-archive-for-splunk.py -f "/opt/plunk/var/lib/splunk/windows/frozendb" -t "/opt/splunk/var/lib/splunk/archived_windows/thaweddb" -i "archived_windows" -o "2014-01-01 00:00:00" -n "2014-10-01 00:00:00" --check_integrity -s "/opt/splunk" --restart_splunk
The script basically selects the buckets and copies them from frozen to the thawed according to the frozen path, thawed path, and the time range you provide.
The integrity check and restarting Splunk is optional here. When data integrity control is enabled, Splunk computes hashes for a bucket, and hash files are stored in the rawdata directory. If the buckets have hashes, you can check their integrity with the script before restoring them. The script logs the integrity check results in three categories inside of the logs directory. The categories are;
- Buckets Failed
- Buckets Passed
- Buckets Have No Data Integrity Check
The integrity check optionally occurs after copying the buckets and before the rebuilding process. If the rawdata has changed in some way, testing the integrity of the bucket will fail. Failed buckets do not participate in the rebuilding process. After obtaining the buckets, the rebuilding process starts with the “splunk rebuild” command. The script also logs the rebuilding process too, and you can see both successfully rebuilt and failed buckets.
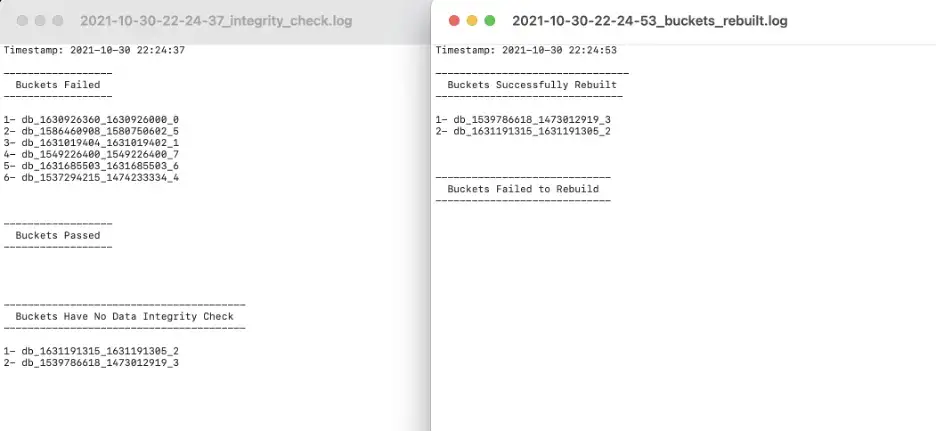
You can check the details here.