Navigating Splunk Implementation (with Enterprise Security): A Practical Approach
In this post, I’d like to go over a Splunk project implementation (on-premises) concerning security. This is based on our experiences as consultants, where we’ve helped numerous organizations overcome common challenges and unlock the power of Splunk for enhanced security insights and streamlined operations. As security professionals ourselves, we understand the critical need for a robust security posture, and Splunk plays a vital role in achieving that. In our work, our goal is to provide a reliable, scalable, and maintainable solution by understanding project requirements and following Splunk’s best practices. However, like any project, it comes with its own set of challenges. In this blog, we’ll explore the journey of implementing a Splunk project, from planning to overcoming hurdles and achieving success. I hope this high-level overview empowers other practitioners (e.g. security teams, architects, consultants, etc.) to navigate Splunk implementations successfully.
Assumption
Before diving into the intricacies of the project, it’s important to establish a few assumptions. Assuming there are no significant business or contractual issues, we can focus our attention on the key aspects of the implementation process. Note that Splunk has significant resources and documentation available online (see References below) and I’m trying to summarize our interpretation based on our years of experience implementing Splunk projects on-premises.
Project Plan
Each project is unique but there are some standards we utilize to provide better estimates of project timelines. At the very least, we need to know the general objectives, sizing (e.g. GB/day), number of data sources, and number of use cases. The more detail we have, the better the project plan and estimates are. Typically a successful implementation can take anywhere from a few months to a year depending on how we schedule our mutual times with the customers. I’d like to provide the steps of the project plan template that we use with our customers.
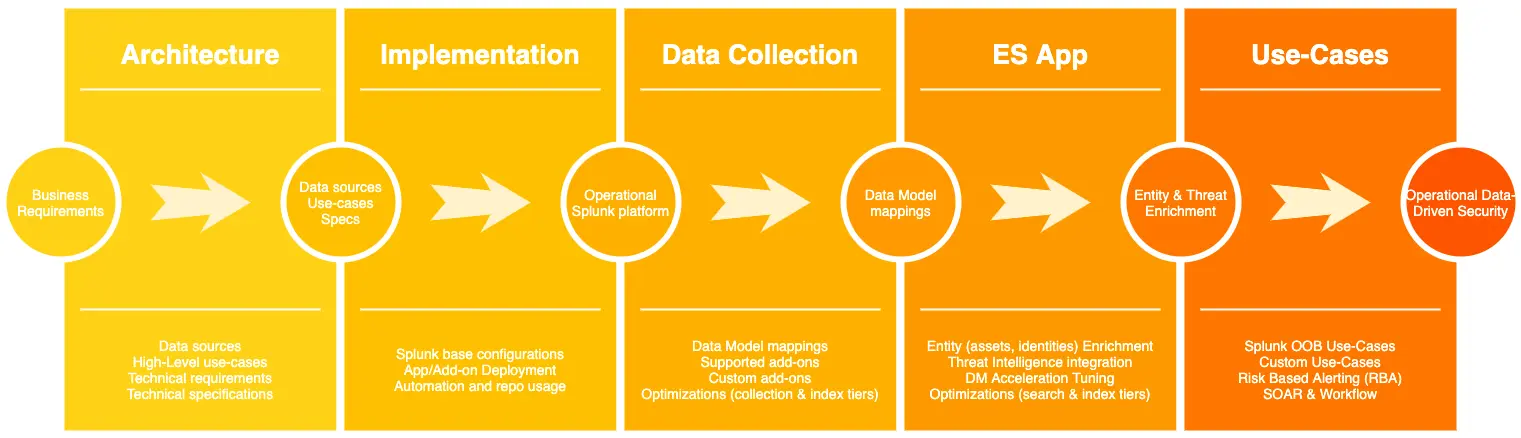 Note: While the plan outlines a general sequence, it doesn’t have to follow a strictly linear approach. We’ve found this method efficient in minimizing dependencies on other teams, which can help streamline the process. However, it’s important to acknowledge that this approach can also limit flexibility in later stages. Some phases, like data collection, application implementation, and use-case development, can be iteratively refined throughout the project.
Note: While the plan outlines a general sequence, it doesn’t have to follow a strictly linear approach. We’ve found this method efficient in minimizing dependencies on other teams, which can help streamline the process. However, it’s important to acknowledge that this approach can also limit flexibility in later stages. Some phases, like data collection, application implementation, and use-case development, can be iteratively refined throughout the project.
1. Architecture and Planning Workshop
Like any project, a project kicks off with engaging workshops to align stakeholders and define project goals, scope, and timelines. Most of the time, we have already determined the high-level requirements and desired architecture for Splunk implementation during POC and pre-sales. In this phase, we dive deeper by referencing Splunk Validated Architectures, infrastructure resources, specifics on data inputs, and use cases.
Notes
- Data questionnaire that details data sources, expected metadata (i.e. index and sourcetypes), and desired retention policies (per index if possible).
- High-level use cases or existing list of correlation searches that need to be covered
- Review of hardware specifications (e.g. existing vs. desired) along with alignment with various departments when necessary (e.g security, infrastructure, storage teams)
2. Splunk Implementation
I have to admit that this is probably the easiest of all the steps in any project. We almost always gather server information (e.g. IP and/or hostname), desired ports for communications (e.g. replication ports, data inputs, etc.), and other requirements such as replication and data retention. Based on this information we prepare the Splunk base configurations before meeting with the customer and make sure necessary commands and scripts (i.e. Ansible playbooks) are ready to be deployed so that during implementation we don’t have to reinvent the wheel but simply review and copy/paste configurations/scripts. Depending on the environment, this step usually takes a few hours unless we are forced to do manual installations. Note that most of our installations are Distributed Clustered Deployment + SHC - Multi-Site (M4 / M14) as per Splunk Validated Architectures, which provides better High-Availability of stored data and increased load distribution (ingest & search) for performance.
Notes
- We have our own Ansible playbooks to install, upgrade, and distribute apps. This speeds up implementation tremendously and reduces any human errors when copying/pasting information.
- When Ansible is not available, we try to create ready-to-implement scripts or playbook-like documentation that can be easily copied and pasted.
- We try to encourage the usage of a repository (i.e. git) to keep all the configurations and provide a single source of truth.
3. Data Collection
The goal at this stage is to make sure we’re collecting all the data that is needed with performance requirements in place while ensuring Common Information Model (CIM) compliance as much as possible. CIM compliance is crucial so that we can utilize out-of-the-box use cases in the Enterprise Security App or develop new ones with (accelerated) Data Models. It is best to have a test or pre-production environment to test and verify various data inputs; however, in practice, this is rarely the case. For standard data sources such as Windows event logs, Palo Alto syslog, etc. we don’t have to do much other than installing the proper add-on and getting the data in. For custom or not-so-standard data sources we usually ask for masked data examples so that we can test and make the proper configurations in our dev/test environment before deploying directly in production.
Notes
- Keeping each data source as a separate task in the project plan helps keep track of progress and allows us to keep specific notes per such task
- We always use Splunk or vendor-built/supported add-ons. For any custom input, it’s usually easier to write our own instead of downloading an unsupported add-on. We keep such add-ons and any SC4S configurations in our repository for future use.
- Especially for custom inputs, make sure to review the following attributes in props.conf:
TIME_PREFIX,TIME_FORMAT,MAX_TIMESTAMP_LOOKAHEAD,SHOULD_LINEMERGE,LINE_BREAKER,TRUNCATE
4. Enterprise Security Application Implementation
Installation of the application is pretty straight forward. For our projects, especially if the customer has experience in more classical or legacy SIEM systems, we need to talk about the Urgency matrix and explain the importance of adding asset and identity information with proper prioritization. The challenge is usually not technical but departmental and policy based depending on customer’s environment. The other important part would be adding new/custom Threat Intelligence sources.
Notes
- For populating identity lookups adding new groups via LDAP queries is pretty easy. The thing to consider would be adding privileged and/or admin groups as separate lookups so that new correlation searches regarding these groups can be added.
- Regarding adding assets, our experience has been variable. While some customers have up-to-date CMDB or similar inventory of their assets that we can periodically retrieve, others have outdated or nonexistent asset inventory, where we have to work with various departments to understand the prioritizations. In such cases, we usually try to add subnets initially to make things easier and then move on to more detailed information.
- Ensure that Data Model accelerations are configured properly by checking the time range, backfill options, and index whitelisting.
5. Use-Case Development
Developing use cases on a clean slate is relatively easier but I’d like to mention the case where we usually transition from an existing SIEM system. It is very likely for an existing system to have hundreds of correlation searches. Based on the projects we’ve done so far, we usually face 200–600 correlation searches on old/legacy SIEM systems that need to be transferred over to the new Splunk installation. Instead of diving directly into rule implementation, we usually spend 1–3 days (depending on content) going over Splunk’s viewpoint. Up to this stage working with Splunk to arrange workshops and trainings for the team is crucial so that we can all speak the same language. This step can become pretty different for each customer since each environment is unique and may have varying requirements. We try to stick to general guidelines and out-of-the-box use cases/analytic stories as starting points and shape our approach accordingly.
Notes
- Review Security Essentials App as well as Content Library – the information can also be found online Splunk Security Content
- Begin with a certain number of popular use-cases/stories. For example, starting with Access, Network, and Endpoint seem to have the most initial coverage (e.g. Access - Brute Force Access Behavior Detected - Rule is a good fit that usually addresses several legacy correlation searches written separately for each data source)
- Track use-case coverage. We’ve done this with Security Essentials App bookmark feature where team members can chime in as needed and use excel or Google Sheets. The best approach is to find a way to work efficiently with the other team members and this turns out to be a very subjective topic.
- Implement any missing use-cases by writing new correlation searches.
- Introduce the concept of Risk Based Alerting
- Integrate with SOAR (if available) or introduce ES App incident workflow so that operation teams can start utilizing Splunk right away.
6. Project Closing
At this stage, the goal is to verify the implementation of previous steps by testing, documentation, and knowledge transfer to ensure a smooth transition to operational use. I find the specific documentation aspect to be very important. It is always best to finish testing and documentation during implementation. Still, in practice (e.g. due to time limitations) we may end up reviewing and doing these tasks at the very end.
Notes
- We recommend having at least 2 Splunk Enterprise Certified Administrators
- Document naming conventions and procedures on data collection (SC4S configuration, UF installation, custom add-on development, etc.) and creating knowledge object (dashboards, searches, lookups, etc.)
- If applicable, document other administrative procedures as well, such as git/Ansible usage with deployment operations
Challenges
As is the case with any project, we always face issues and challenges throughout the implementation. I’ve tried to list some of the major ones below:
- Resource Availability: Adequate resources, both human and technical, are crucial for successful implementation. Clear resource allocation and contingency planning can mitigate this challenge. We also may need to plan some phases of the project iteratively in order to accomodate available resources.
- Interdepartmental Communication: Interdepartmental communication gaps at the customer’s end can hinder progress. Facilitating collaboration and establishing effective communication channels are vital. Most of the time we try to be involved in every aspect in order to better communicate the requirements on our end with various departments.
- Multiple Project Managers: Dealing with multiple project managers can lead to confusion and conflicting priorities. Streamlining communication and decision-making processes can address this issue. We also keep everyone involved up to date with weekly progress reports and planned meetings when necessary.
- Customer Training: Equipping the customer with the necessary training and knowledge is key for maximizing the benefits of Splunk. Comprehensive training programs and ongoing support are essential. In addition to recommended official Splunk training it is also helpful to organize Splunk hands-on workshops to get the teams up to speed with Splunk platform.
- Project Workshop Challenges: Incorrect or incomplete information gathered during workshops, such as disparate data formats or sources, can pose challenges. For example, it is not unusual to get a few (or many) new data sources after implementation phases. Depending on how much detail we have during these workshops, we try to put some buffer in the project plan accordingly based on our previous engagements.
Conclusion
Implementing a Splunk project requires meticulous planning, effective communication, and a proactive approach to challenges. By leveraging the platform’s capabilities and addressing these hurdles head-on, organizations can unlock valuable insights from their data, leading to improved operational efficiency and informed decision-making. While the specifics may differ, the core principles of planning, communication, and overcoming challenges can be applied to many data-oriented projects. I encourage you to share your own experiences and feedback in the comments below. This outline, based on our experience, can serve as a starting point for navigating similar projects and unlocking the power of data for your organization.
References:
- Splunk Validated Architectures
- Splunk Success Framework
- Splunk Security Content
- Build integrations for Splunk Enterprise Security
- Splunk Enterprise Security
- Splunk ES Content Update
- Security Essentials App