🧊 Restore Splunk Frozen Buckets Easily: Local, S3, or Custom S3-Compatible Storage
In Splunk Enterprise, frozen buckets represent the final stage of the index lifecycle; data that has aged beyond its retention policy and has been archived to save space. Depending on your setup, these frozen buckets may be written to local directories, AWS S3, or custom S3 compatible endpoints.
But what happens when you need to access that archived data again?
Splunk provides a way to restore archived frozen buckets into the thaweddb directory of an index, making the data searchable once more without reindexing.
In this post, we’ll introduce a flexible Python script that simplifies this restore process, whether your archive is stored:
- Locally 🗄️
- In AWS S3 or on custom S3-compatible storage ☁️
The script can also extract the oldest/newest event times for specific indexes in your archive, helpful for compliance checks or selective recovery.
The script can also extract the oldest/newest event times for specific indexes in your archive, helpful for compliance checks or selective recovery — all powered by seynur-tools/restore_archive_for_splunk on GitHub.
1. 🔄 Restore Methods Overview
Whether your archived frozen buckets are stored locally, in AWS S3, or in a custom S3-compatible endpoint (like LocalStack or MinIO), this script has you covered.
Here’s what it supports:
📦 Archive Location | 🔄 Restore Capability | 🕰️ Timestamp Discovery | 🧰 Example Use Cases
------------------------|-------------------------|-------------------------|-------------------------------------------------
Local filesystem | ✅ Yes | ✅ Yes | On-prem archival, manual storage
AWS S3 | ✅ Yes | ✅ Yes |Cloud-native storage, backup/restore
S3-compatible endpoints | ✅ Yes | ✅ Yes | LocalStack for dev/test, MinIO hybrid use
For each method, the script will:
- 🔍 Detect available frozen buckets in the specified source location (local directory or remote storage).
- 📄 Validate the presence of essential files, especially journal.zst, within each bucket.
- 📥 Retrieve the required files from:
- Local filesystem (direct file access)
- AWS S3 or custom endpoints (using aws s3api get-object)
- 📂 Recreate the bucket structure under the appropriate index’s thaweddb directory.
- 🔎 Make the data instantly searchable in Splunk without restarting or reindexing.
💡 The script does not require full bucket contents — it restores only what Splunk needs (journal.zst) to bring the data back online.
🕰️ Bonus - Timestamp Discovery: You can also retrieve the oldest and newest event timestamps for a specific index from your archive. This is ideal for estimating time ranges covered by archived data.
2. 🧪 Usage Scenarios
This script can restore frozen buckets from various archive locations and supports timestamp discovery for compliance or selective recovery. Let’s walk through four example use cases:
- Restoring from Local Directory
- Restoring from AWS S3 and a Custom S3-Compatible Endpoint (e.g., LocalStack)
- Only get min/max event timestamps without restoring
We’ll go step by step and show how the script performs in each scenario: restoring data to Splunk’s thaweddb directory so that it’s instantly searchable.
Before testing scenarios, let’s set up test environments. To simulate realistic conditions, we’ve configured two indexes in Splunk:
Index = oyku_test_local: This index archives frozen data directly to a local folder. Also my local frozen bucket is <MY-LOCAL-FROZEN-PATH>/oyku_test_local/db_1764140400_1764140400_0
Note: Don’t forget to change “
<my-local-frozen-path>” path. 🐣
[oyku_test_local]
coldPath = $SPLUNK_DB/oyku_test_local/colddb
homePath = $SPLUNK_DB/oyku_test_local/db
thawedPath = $SPLUNK_DB/oyku_test_local/thaweddb
coldToFrozenDir = <my-local-frozen-path>/oyku_test_local/
frozenTimePeriodInSecs = 10
maxHotSpanSecs = 10
maxHotBuckets = 1
maxWarmDBCount = 1
Index = oyku_test_s3: This index pushes frozen data to a LocalStack S3-compatible bucket using a coldToFrozenScript.
[oyku_test_s3]
coldPath = $SPLUNK_DB/oyku_test_s3/colddb
homePath = $SPLUNK_DB/oyku_test_s3/db
thawedPath = $SPLUNK_DB/oyku_test_s3/thaweddb
coldToFrozenScript = "$SPLUNK_HOME/bin/python" "$SPLUNK_HOME/etc/apps/org_frozen_buckets_to_cloud_app/bin/coldToS3.py"
frozenTimePeriodInSecs = 10
maxHotSpanSecs = 10
maxHotBuckets = 1
maxWarmDBCount = 1
📌 You can find more about setting up this LocalStack environment in my previous blog post: Archiving Splunk Frozen Buckets to S3 on LocalStack.
Additionally, the arguments for the LocalStack S3-compatible bucket use case are listed below.
custom S3 repo = s3-frozen-test-bucket
custom frozen bucket = db_1764140400_1764140400_0
custom endpoint-url = http://localhost:4566
2.1. 🗄️ Restoring from Local Directory
In this example, we’ll restore a frozen bucket that was previously archived on the local filesystem under the path defined in indexes.conf as the frozen path.
🧪 Step-by-step: Restore the Local Bucket
We’ll now run the restore script, pointing it to the local archive root (this path should be your <my-local-frozen-path> directory) and specifying the index name as oyku_test_local.
command:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-frozen-path>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" -i "oyku_test_local" -o "2025-11-26 00:00:00" -n "2025-11-26 12:00:00" -s "$SPLUNK_HOME" --restart_splunk
✅ expected output:
---------------------------
The number of bucket(s) found in the local path: 1.
---------------------------
Copying Buckets...
Buckets are successfully moved...
---------------------------
Buckets rebuild completed.
Success: 1, Failed: 0
---------------------------
Restarting Splunk...
... <splunk restarting messages> ...
The Splunk web interface is at https://oyku.host:8000
%
After running the script, the restored data becomes immediately searchable in Splunk: no reindexing or restart required, as in Figure 1. 🌸
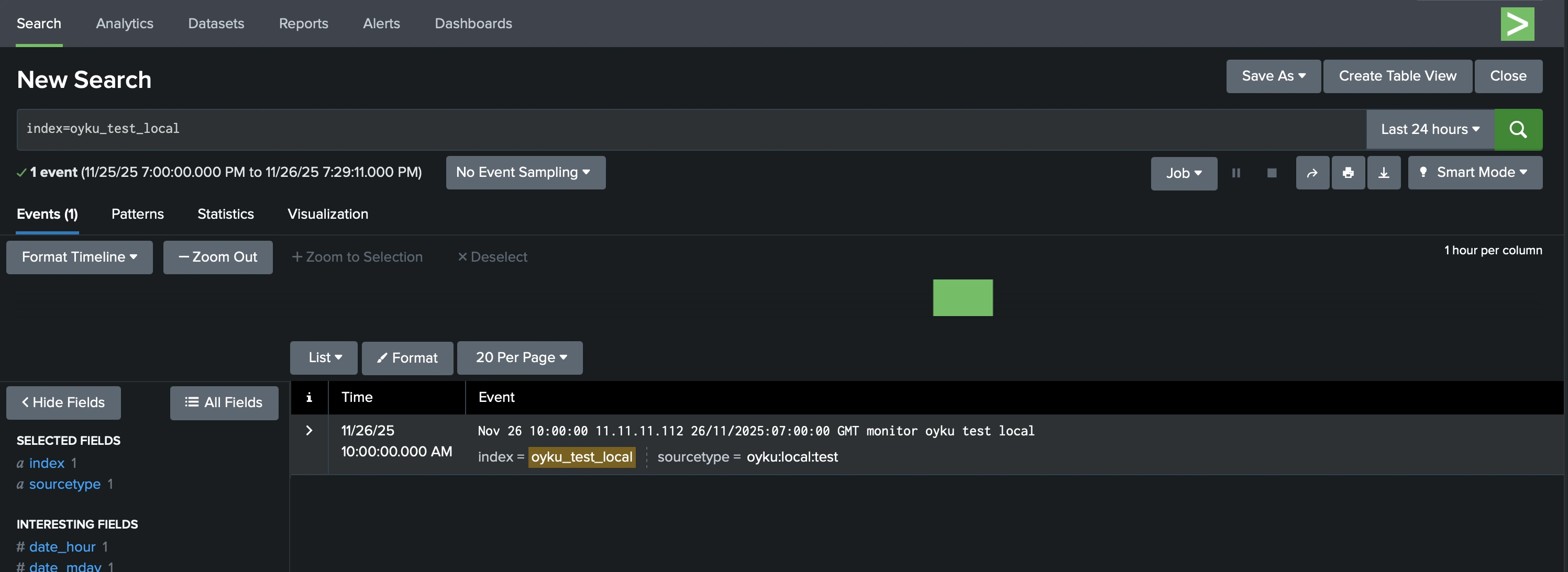 |
|---|
| Figure 1 Local - Thawed data result on the Splunk. |
2.2. ☁️ Restoring from AWS S3 or Custom S3-Compatible Endpoint
Our restore script is capable of retrieving archived frozen buckets directly from AWS S3, or any custom S3-compatible endpoint, such as LocalStack or MinIO.
In this example, we will simulate a production-like environment using LocalStack, but the process is the same for AWS S3.
The script will:
- Use
aws s3api get-objectto download thejournal.zstfile. - Place the file in the appropriate
thaweddbdirectory. - Make the data instantly searchable in Splunk.
The archived bucket mentioned was previously uploaded to LocalStack using the coldToS3.py script, as discussed in my blog post titled “Archiving Splunk Frozen Buckets to S3 on LocalStack”. If you’re not familiar with LocalStack, I recommend checking out my other blog, “Getting Started with LocalStack: Local S3 Bucket Creation and File Operations”.
🧪 Step-by-step: Restore the S3 Bucket
To restore from AWS S3, simply specify the S3 repository name and index. The script utilizes your environment’s default AWS credentials and region.
command for S3 - AWS:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-s3-frozen-path-to-be>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" --index="oyku_test_s3" --s3_default_bucket="s3-frozen-test-bucket" -o "2025-11-26 00:00:00" -n "2025-11-26 12:00:00" -s "$SPLUNK_HOME" --restart_splunk
✅ expected output:
---------------------------
---------------------------
Listing and filtering S3 buckets from default AWS endpoint...
The number of bucket(s) found in S3: 1.
Downloading oyku_test_s3/db_1764140400_1764140400_0/rawdata/journal.zst to <my-local-s3-frozen-path-to-be>/frozen/oyku_test_s3/db_1764140400_1764140400_0/rawdata/journal.zst
{
"AcceptRanges": "bytes",
"LastModified": "2025-11-26T15:00:01+00:00",
"ContentLength": 341,
"ETag": "\"7fd961f9025782121d3cd6a87ba55fd4\"",
"ChecksumCRC64NVME": "xbyZkm8VCpA=",
"ChecksumType": "FULL_OBJECT",
"ContentType": "binary/octet-stream",
"ServerSideEncryption": "AES256",
"Metadata": {}
}
---------------------------
The number of bucket(s) found in the local path: 1.
---------------------------
Copying Buckets...
Buckets are successfully moved...
---------------------------
Buckets rebuild completed.
Success: 1, Failed: 0
---------------------------
Restarting Splunk...
... <splunk restarting messages> ...
The Splunk web interface is at https://oyku.host:8000
%
To restore frozen buckets from a custom S3 endpoint, add the --s3_path parameter to the previous command.
command for S3 - Custom Endpoint:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-s3-frozen-path-to-be>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" --index="oyku_test_s3" --s3_default_bucket="s3-frozen-test-bucket" --s3_path="http://localhost:4566" -o "2025-11-26 00:00:00" -n "2025-11-26 12:00:00" -s "$SPLUNK_HOME" --restart_splunk
✅ expected output:
---------------------------
---------------------------
Listing and filtering S3 buckets from custom endpoint: http://localhost:4566
The number of bucket(s) found in S3: 1.
Downloading oyku_test_s3/db_1764140400_1764140400_0/rawdata/journal.zst to <my-local-s3-frozen-path-to-be>/frozen/oyku_test_s3/db_1764140400_1764140400_0/rawdata/journal.zst
{
"AcceptRanges": "bytes",
"LastModified": "2025-11-26T15:00:01+00:00",
"ContentLength": 341,
"ETag": "\"7fd961f9025782121d3cd6a87ba55fd4\"",
"ChecksumCRC64NVME": "xbyZkm8VCpA=",
"ChecksumType": "FULL_OBJECT",
"ContentType": "binary/octet-stream",
"ServerSideEncryption": "AES256",
"Metadata": {}
}
---------------------------
The number of bucket(s) found in the local path: 1.
---------------------------
Copying Buckets...
Buckets are successfully moved...
---------------------------
Buckets rebuild completed.
Success: 1, Failed: 0
---------------------------
Restarting Splunk...
... <splunk restarting messages> ...
The Splunk web interface is at https://oyku.host:8000
%
Just like with local restoration, there’s no need to restart Splunk: your data will be searchable right away (Figure 2).
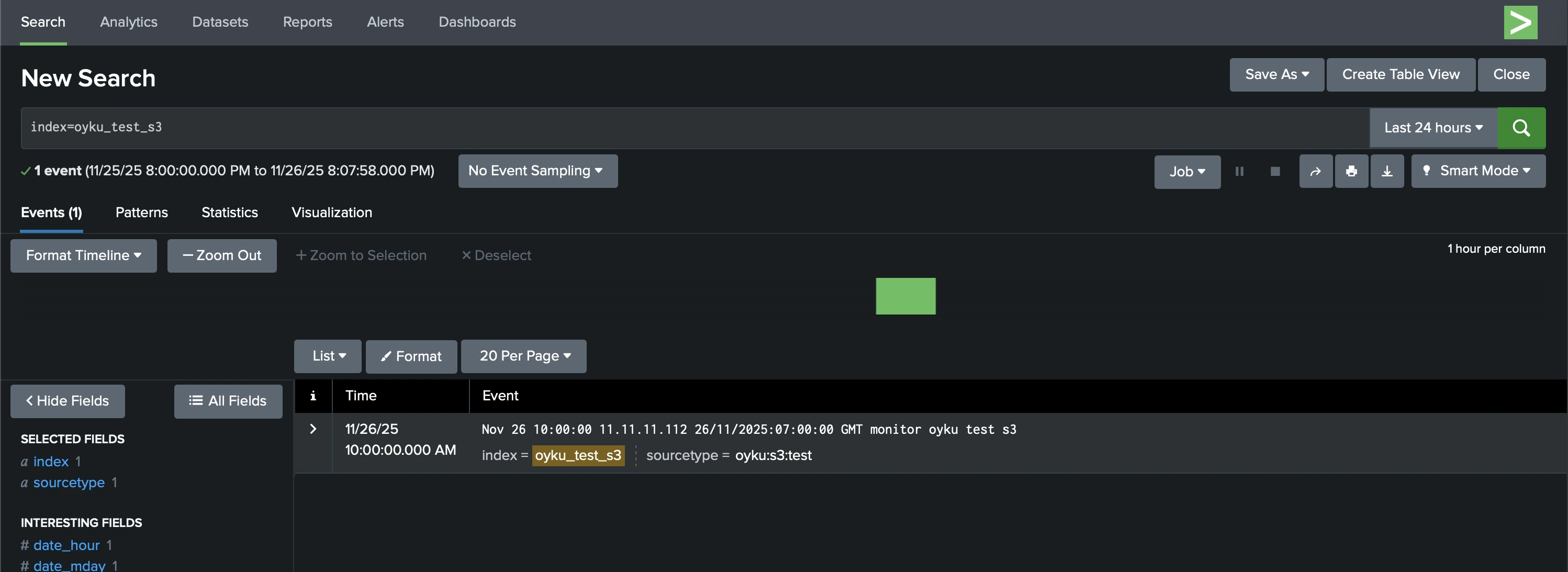 |
|---|
| Figure 2 S3 - thawed data result on the Splunk. |
2.3. 🕰️ Discovering Min/Max Event Timestamps Only
Sometimes, you don’t need to restore all frozen data; you just want to know what time ranges are available in the archive.
Whether you’re auditing logs, checking data coverage, or planning selective restores, the script allows you to query only the min/max timestamps from your archive without restoring anything.
🧪 Usage Example (Local Directory)
command:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-frozen-path>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" -i "oyku_test_local" -s "$SPLUNK_HOME"
✅ expected output:
---------------------------
Listing and filtering S3 buckets from custom endpoint: http://localhost:4566
The number of bucket(s) found in S3: 1.
---------------------------
For 'oyku_test_s3' index
Oldest date: '2025-11-26 10:00:00', newest date: '2025-11-26 10:00:00'.
🧪 Usage Example (S3 - AWS)
command:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-s3-frozen-path-to-be>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" --index="oyku_test_s3" --s3_default_bucket="s3-frozen-test-bucket" -s "$SPLUNK_HOME"
✅ expected output:
---------------------------
Listing and filtering S3 buckets from default AWS endpoint...
The number of bucket(s) found in S3: 1.
---------------------------
For 'oyku_test_s3' index
Oldest date: '2025-11-26 10:00:00', newest date: '2025-11-26 10:00:00'.
🧪 Usage Example (S3 - Custom Endpoint)
command:
python3 <restore-archive-repo-path>/restore-archive-for-splunk.py -f "<my-local-s3-frozen-path-to-be>/" -t "$SPLUNK_DB/oyku_test_local/thaweddb/" --index="oyku_test_s3" --s3_default_bucket="s3-frozen-test-bucket" --s3_path="http://localhost:4566" -s "$SPLUNK_HOME"
✅ expected output:
---------------------------
Listing and filtering S3 buckets from custom endpoint: http://localhost:4566
The number of bucket(s) found in S3: 1.
---------------------------
For 'oyku_test_s3' index
Oldest date: '2025-11-26 10:00:00', newest date: '2025-11-26 10:00:00'.
⚠️ Note: The script directly extracts min/max times from the
journal.zstfile, similar to how Splunk operates. There’s no need to decompress or manually inspect the raw data.
3. 🎁 Wrapping Up
Managing archived data in Splunk doesn’t have to be a pain. Whether your frozen buckets live on local disks, in AWS S3, or a custom S3-compatible service like LocalStack or MinIO, this script gives you full control over:
- ♻️ Restoring buckets into Splunk’s thaweddb for instant search
- 🧠 Discovering min/max event times for planning or audits
- ⚙️ Supporting multiple storage backends, all from a single command-line utility
This lightweight, flexible tool makes it easy to rehydrate archived data without reindexing or restarting Splunk, perfect for incident investigations, audits, or long-term searchability.
💬 Questions? Use cases? Want to showcase your own restore flow? I’d love to hear about it!
Connect with me on LinkedIn or drop a comment on the blog.
Until next time 🚀📦
References:
- [1] Seynur (2025). restore_archive_for_splunk [GitHub repository]. GitHub. https://github.com/seynur/seynur-tools/tree/main/restore_archive_for_splunk
- [2] Can, Ö. (2025). Getting Started with LocalStack: Local S3 Bucket Creation and File Operations. http://blog.seynur.com/localstack/2025/10/24/getting-started-with-localstack-local-s3-bucket-creation-and-file-operations.html
- [3] Can, Ö. (2025). Archiving Splunk Frozen Buckets to S3 (via LocalStack). http://blog.seynur.com/localstack/2025/10/28/archiving-splunk-frozen-buckets-to-s3-on-localstack.html